|
<< Click to Display Table of Contents >> Collections |
  
|
|
<< Click to Display Table of Contents >> Collections |
|
Sometimes an equation requires information, not about a single entity, but about a collection of entities. Such variables are called aggregate variables. An aggregate variable might be the number of rabbit entities in your model. Or the average height of all the tree entities in your model. Or the maximum of the revenues generated by senior sales representatives in the northeast region. All these aggregates are properties of collections.
A collection is a set of entities of the same type. A collection can be very inclusive (all entities of type "performer"). Or a collection can partition entities into sub collections based on their attributes. Partitioning by the "gender" attribute gives subcollections of male performers and female performers. Partioning by both "gender" and "talent" attributes will give subcollections of male dancers, male singers, male jugglers, female dancers, female singers, and female jugglers. Collections can be empty: for example, at certain times there may be no female singer entities in the model. If halfway through a simulation, a new performer arrives with talent "sword-swallower", then subcollections of male sword-swallowers and female sword-swallowers will come into existence as well.
The most basic collection comprises ALL the entities of a given type. Collections are indicated by square brackets [] after the name of the entity type. If nothing is inside the brackets, the collection includes all entities of that type.
You don't have to do anything to create a full collection. The collection of all entities of a type is automatically defined when the entity type is created, and you can see it on the collections tab of the entity type inspector.
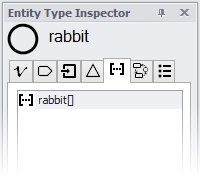
You'll sometimes want to calculate statistics for a subset of all entities of a type. Subcollections are defined by entities' attributes. For example, rabbits might have a "color" attribute. Before you can calculate the average weight of all white rabbits, or the number of brown rabbits, you must create a collection of rabbits that has been partitioned into subsets by color. To do this, click the "new collections" button ![]() at the bottom of the collections tab of the entity type inspector. You will be given a list of available attributes.
at the bottom of the collections tab of the entity type inspector. You will be given a list of available attributes.
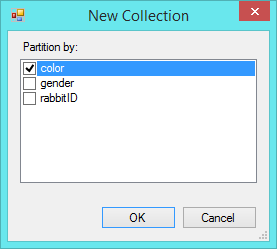
Select "color", and a new collection will be created and will appear as rabbit[color] (pronounced "rabbit by color"). This collection represents the full population of rabbits, partitioned into subsets by color. You will also see a new Collection Inspector for the rabbit[color] collection, used to view and set properties of the new collection. More about that in "adding properties to collections" below.
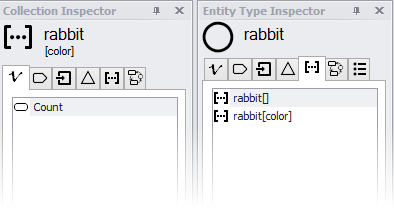
You can also create subcollections using more than one attribute. Selecting "color" and "gender" as key attributes of the subcollection will create the collection rabbit[color,gender].
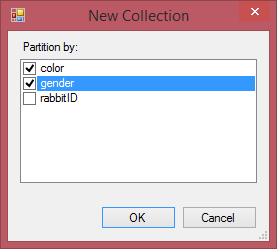
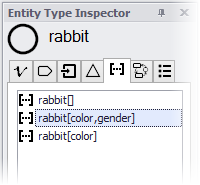
This collection partitions the full population into subsets of rabbits by gender and color, and can be used to calculate aggregate variables such as the average age of brown male rabbits.
We use the word "collections" to refer both to full collections and to subcollections.
When you modify the attributes of an entitytype, you may wish to propagate some of those changes into subcollections as well. For example, if you delete an attribute in the parent entity, any subcollections using that attribute will be invalid, yielding an error message:
![]()
Similarly, if you add an attribute to the parent entity, you may wish to add it to the subcollection keys as well.
Fortunately repairs and modifications to subcollection keys are easy. Right-click the subcollection and select "Edit Key attributes":
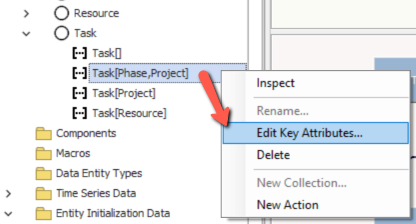
This will bring up the collection's attributes dialog:
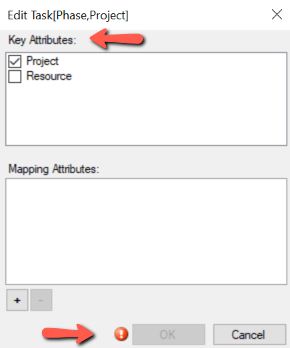
Note that an error indicator will be shown, as above, if your attribute selections create a duplicate conflicting with an existing subcollection. You will not be able to make changes until you correct the conflicting selection.
Collections are entities in their own right: they appear in the model overview, they can be seen in entity inspectors, and most importantly, you can add variables, attributes, and references. Collections can also have diagrams showing the structure of any properties that have been added.
If you wish to add your own properties to a collection, double-click the name of the collection in the model inspector to open a collection inspector. Add variables and attributes in the inspector, or in a diagram, as you would for an entity.
The variable Count is automatically included with every collection, and reports the number of entities existing in the collection at each point in time.
Aggregates of any of an entity type's variables are available for collections of that type. If your rabbit entities have a variable called "ear length", then any collection or subcollection of rabbit entities can provide the average, sum, maximum, minimum, median, product or standard deviation of the ear lengths of its members. To create an aggregate variable, drag the Aggregate variable node from the palette onto a diagram, or click the "new aggregate variable" button on the variable tab of the collection inspector. Right-click the variable to edit it and choose the aggregation function from the pull-down menu, as well as the target variable.
Aggregate variables are named automatically, based on their definition. For example, the aggregate variable that computes the median of the ear lengths of a collection of rabbits will automatically be called "median ear length".
If there are no entities in the collection being evaluated, then Min, Max, Average, StDev and Median will return NaN. Count, Sum and Product will return zero. You can override these defaults in the aggregate equation editor.
Aggregates can be created by dragging from the diagram toolbar, or clicking the button in the collection inspector toolbar:

Then edit the new aggregate to select the function and target variable (required), and "If Empty" expression (optional):
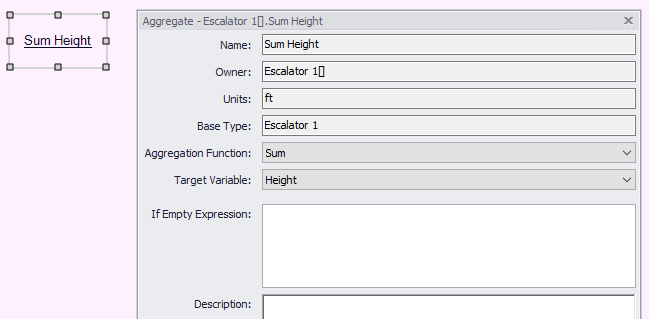
Each aggregation function performs an operation on the vector of Target Variable values among the collection members.
Aggregation Function |
Units (input -> output) |
Default If Empty |
Notes |
Sum |
x -> x |
0 |
Sum of target variable |
Average |
x -> x |
NaN |
Average or mean |
Min |
x -> x |
NaN |
Minimum value |
Max |
x -> x |
NaN |
Maximum value |
Median |
x -> x |
NaN |
Median value - relatively expensive to compute, so you may wish to use it sparingly. |
StDev |
x -> x |
NaN |
Standard deviation |
Prod |
dmnl -> dmnl (not strictly enforced at present) |
0 (often 1 may be a better choice, and we recommend overriding with this value if needed) |
Product |
SumSq |
x -> x*x |
0 |
Sum of squares of the target variable (useful for computing errors or likelihoods) |
SumAbs |
x -> x |
0 |
Sum of absolute values of the target variable (useful for computing errors or likelihoods) |
PoissonBinomialCDF |
dmnl -> dmnl (not strictly enforced at present) |
NaN |
CDF of the PoissonBinomial distribution, where the target variable is a vector of success probabilities [0,1] for the set of trials. The CDF is formally P( X <= n required | trial probabilities ) where X is a random variable with the PoissonBinomial distribution. |
PoissonBinomialPMFrange |
dmnl -> dmnl (not strictly enforced at present) |
NaN |
PMF (probability mass function, often loosely known as density) of the PoissonBinomial distribution, over a range from Start to End. This is formally P( start <= X <= end | trial probabilities ). If start=end, the normal PMF, P(X=n) is obtained. |
Once you have defined an aggregate or other variable in a collection, other entities may use that information. To do so, they must have a reference to the collection.
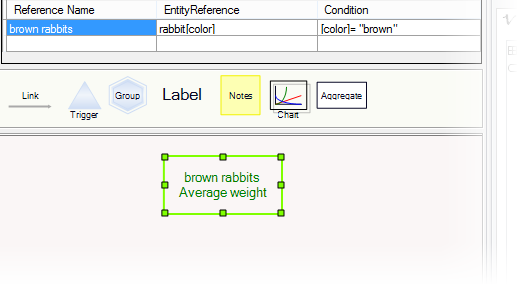
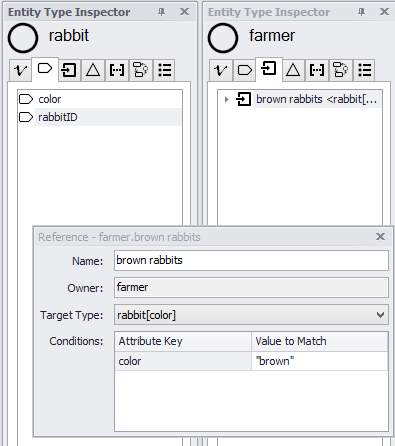
To create a reference to a collection, click the "new reference" button at the bottom of the reference tab, and choose the desired collection under "target type". If the target type is a partitioned collection you will need to specify which subcollection you require. For example, for a farmer entity to have access to average weight of brown rabbits, start with rabbit entities having an attribute called "color". Then,
1. Create a new collection of rabbits, subdivided by color. (Choose "new collection", and when prompted for the attribute, choose "color").
2. In the farmer entity, create a new reference called "brown rabbits", of type rabbit[color]. You will be prompted to enter a value to match for "color". Enter "brown".
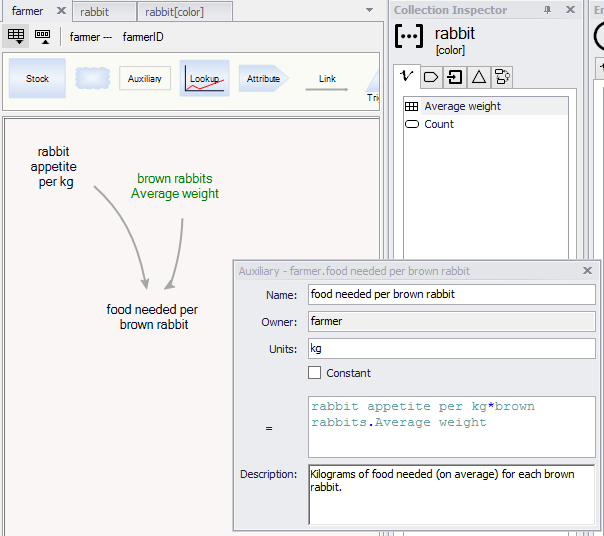
If you have added an aggregate variable to the partitioned collection rabbit[color], it is now available through the reference. For example, if rabbits have a weight variable, and if you have added an average weight variable to the rabbit[color] collection, the average weight of brown rabbits can now be accessed in the farmer's equations as "brown rabbits.average weight":
If you create an aggregate variable and drag it to the diagram of an entity type that will use it, Ventity will automatically create the reference for you. However the reference will be incomplete until you supply the attribute value to match. If in the example above, you did not create the reference but instead dragged Average weight from the rabbit[color] inspector to the farmer diagram, you would see a shadow appear called "rabbit_color.Average weight" (Item 1 in the figure below), and a reference appear called "rabbit color" (item 2 in the figure below).
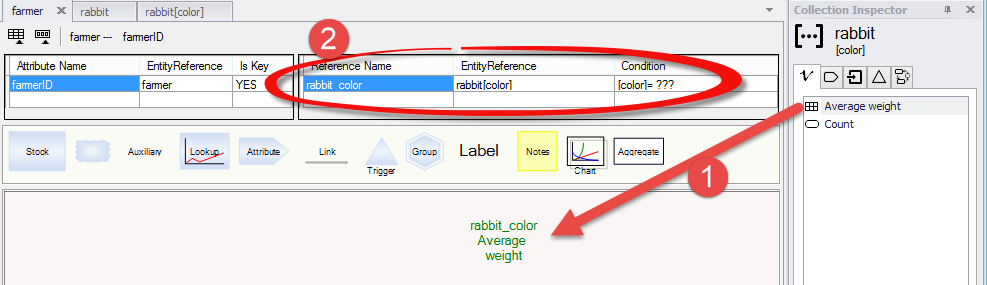
The three quesiton marks in the reference indicate that the reference is not complete. To complete it, edit the reference by double clicking it in the reference grid, and set the value to match should be "brown". You might also at this time rename the reference to be more specific ("brown rabbits"):
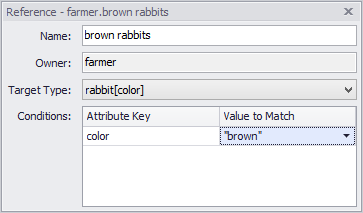
which will rectify the situation: